AWS 기반으로 CodeCommit 과 연동하여 개발을 하다보면 Windows 기반의 Eclipse 연동을 주로 사용합니다.
AWS 에서 IntelliJ 가 아닌 Eclipse plugin 을 사용하라고 가이드 하는 것은 아마도 Eclipse 가 오픈소스 IDE 툴 이기 때문에 aws plugin 을 만들어서 배포하기데 적절하기 때문이 아닌가 하고 생각이 드네요.
저는 Mac 기반의 Eclipse 를 사용하는데 AWS CodeCommit 과 연동시키는데 몇시간을 고생해서 해결한 내용을 설명하고자 합니다.
Eclipse 를 설치하기 전에 먼저 JDK 가 설치되어야 하는데, 이전 글에서 Mac 에 JDK 를 설치하는 것은 설명을 드렸습니다.
다음으로 Eclipse 설치는 그냥 Applications 아이콘에 복사만 하면 되므로 Eclipse 설치는 생략...
Eclipse 에서 AWS toolkt 설치는 "메뉴 >> Help >> Install New Software..." 창을 띄우고 "Work with" 레이블이 있는 Text 상자에 "https://aws.amazon.com/eclipse/site.xml" 를 입력해서 software 를 설치하면 됩니다.
AWS CodeCommit 을 사용하기 위해서는 "IAM >> Users" 의 Security Credentials 탭에서 "HTTPS Git credentials for AWS CodeCommit" 항목에 사용자를 등록하면 사용할 수 있습니다.
그리고 AWS CodeStar 에서 Project 를 하나 만들면, CodeCommit Repository 가 생성이 되고, 이 Project 의 Team 메뉴에 위의 IAM User 를 할당해 주면 해당 User 가 CodeCommit 을 사용할 수 있습니다.
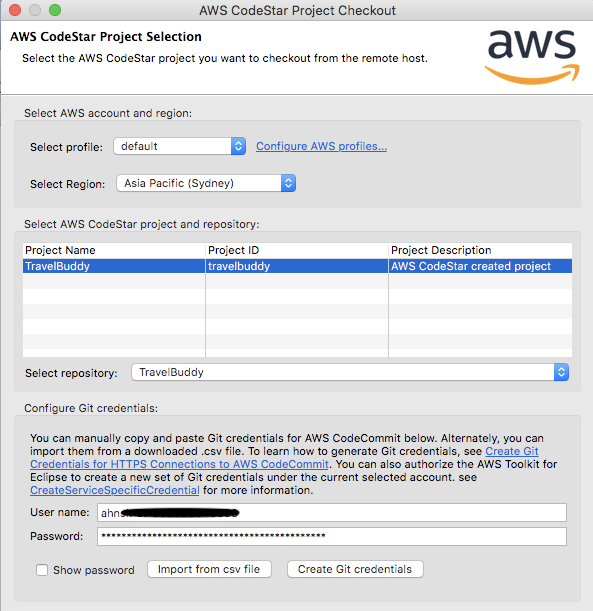
이제 Eclipse 의 주황색 아이콘을 클릭해서 CodeCommit 의 repository 로 부터 소스를 받아오겠습니다.
AWS Access Key ID, Secret Access Key 를 넣고 region 을 선택합니다. 그리고 CodeCommit 의 git id 와 패스워드를 입력하면 소스를 다운받을 수 있습니다.
하지만 다운을 받다가 에러가 발생하면서 실패하게 됩니다.
이 부분에서 고생을 많이 했었는데..
1. 처음에는 Oracle Java 에서 나는 문제로 오해해서 Mac 에 OpenJDK 를 설치했습니다. 그리고 Eclipse 를 띄울 때 OpenJDK 를 사용할 수 있게 수정했습니다.
그래도 똑같은 에러가 발생했습니다.
2. 그래서 JGit 의 버그로 생각하고 5.9 버전에서 낮은 버전으로 다시 설치했습니다.
그래도 에러가 발생.
3. IAM User 에서 https git credential 을 지우고 다시 생성하면 된다고 구글리에 나와 있어서 다시 했지만 또 에러.
마지막으로 아래 부분을 적용했더니 해결.
4. Eclipse "Preferences > General > Security > Secure Storage" 에서 OS X keystore 연동 체크박스를 해제
결국은 Mac 에서 keychain 연동할 때 eclipse 의 security storage 와의 이슈 때문이었습니다.
저는 OpenStack 을 오랫동안 해왔기 때문에 OpenStack 의 Neutron 로 비교하면 이해가 더 쉽게 되더라고요.
먼저 네트워크 대역을 만들기 위해서는 VPC 가 필요합니다. virtual 하게 만드는 것이기 때문에 10.0.0.0/16 과 같이 사설망 대역을 사용합니다.
그리고 외부와의 통신을 위해서는 Internet gateway (IGW)를 생성합니다. 이것은 software gateway 라고 생각이 들고 여기까지는 VPC 와 상관이 없습니다. 그래서 이해하기 쉽게 IGW 를 VPC 바깥에 그렸습니다.
IGW 를 VPC 와 연결 (associate) 하는 순간에 port 가 생성되어 연결될 것으로 보입니다.
VPC 내에는 subnet 을 만들어 Network 대역을 다시 나눌 수 있는데 subent 은 10.0.0.0/24 처럼 VPC 대역 내여야 하고, 하나의 subent 은 AZ 의 하나에만 할당될 수 있습니다. AZ 내에 하나만 할 당 할 수 있는 이유는 EC2 VM 을 만들면 VPC 내의 Subnet 을 선택하고, VM에 ip 를 할당하면서 해당 IP 에 대해서 s/w 적으로 연결이 될텐데 여러 AZ 에 대역이 펼쳐져 있으면 통신이 꼬일 수 밖에 없습니다.
그러므로 실제로 중요한 것은 VPC 라기 보다는 Subnet 입니다. Subnet 의 정보를 가지고 다 처리를 하는데 다만 통합적으로 관리할려고 VPC 라는 개념을 가져온 것 뿐입니다.
Subnet 은 라우팅을 잡아야 하는데, 내부적으로는 VM 을 관리하는 Baremetal Host 서버에 라우팅을 세팅하기 위한 방법이 필요합니다. (혹은 Baremetal 에 떠 있는 software network switch 에서 라우팅을 세팅)
그래서 라우팅 테이블을 만들고 Subnet 에 연결(assocation) 해주면 그 라우팅 정보를 가지고 있다가 VM 이 생성될 때 세팅을 해줄 수 있습니다.
정리해보면 다음과 같습니다.
1. IGW 는 VPC 에 attach 하는 부분이 필요하다. (router 에서 인터넷으로 가는 GW port 를 연결하는 작업)
2. Route table 을 Subnet 에 association 하는 부분이 필요하다 ( VM 이 생성될 때 통신될 수 있도록 라우팅을 세팅해야 하므로 해당 정보를 이용)
AWS 가 내부적으로 어떻게 구성되어 있는 지는 모르겠습니다. 하지만 OpenStack Neutron 을 보면 저런 방법을 사용하고 있기 때문에 아마도 동작 방식은 비슷하지 않을까 생각합니다.
Istio 는 Kubernetes 에만 올릴 수 있고 Control plane 이 여러 pod 로 구성되어 있습니다.
1.4 버전까지는 아래 다이어그램에서 보이듯이 Control 에 해당하는 컴포넌트들이 각각의 프로세스로 실행되었습니다.
하지만 1.5 버전 부터는 (현재는 1.6 버전이 최신입니다) 아래와 같이 New Architecture 로 변경되었습니다.
모든 컴포넌트가 istiod 라는 하나의 프로세스로 합쳐지고 Mixer 가 없어지고 Pilot 이 Mixer 의 기능까지도 함께 수행하는 것으로 되어 있습니다.
Istio 에서는 각 서비스를 관리하는 것도 중요하지만 사실 더 중요한 것은 여기 다이어그램에는 표시되지 않은 Ingress traffic 을 처리하는 Gateway 서버입니다. 모든 트래픽을 받아는 주는 관문 역할을 해야 하고, 백엔드의 Envoy Proxy 와도 연계되어야 하기 때문에 Isito 를 도입한다면 중요하게 고려되어야 할 서비스입니다.
[ 1 day ] OpenStack 소개 (2H) - OpenStack 배경, 구성요소, 아키텍처, 기능 등을 설명 OpenStack 설치 실습 (4H) - OpenStack 기본 설정 설치 (cinder 제외, tenant network 로 설정) OpenStack Cli 실습 (2H) - OpenStack Cli 활용 실습
[ 2 day ] OpenStack Identity 관리 (1H) - Keystone 설정, 기능 설명과 명령어를 실습 OpenStack Image 관리 (4H) - Glance 설정, 기능 설명 - Diskimage-builder 를 활용한 이미지 생성, cloud-init 활용 - 명령어 실습 Ceph 스토리지 관리 (4H) - Ceph 스토리지 기본 설명 및 설치 실습 - Cinder 설치, 설정, 기능 설명 - 명령어 실습
[ 3 day ] OpenStack 네트워크 관리 (8H) - Neutron 기능 설명 - provider network 설정, 기능 설명 - tenant network 설정, 기능 설명 - OVN (Open Vistual Network) 설명
[ 4 day ] OpenStack Compute 관리 (4H) - Nova Compute 설정, 기능 설명 - Live migration, evacuation, 노드 활성화,비활성화 실습 OpenStack 종합 실습 (4H) - 로그를 통한 문제 해결 방법 - Custum image 생성, 등록, VM 인스턴스 생성 등의 모든 기능을 실습
Kubernetes Upgrade 는 고려해야 할 사항이 많지만 Kubespray 를 활용하면 의외로 간단할 수 도 있다.
Kubespray 는 Kubernetes 설치에 kubeadm 을 활용하기 때문에 업그레이드는 Kubernetes 의 바로 윗단계 마이너버전까지만 가능하다. 예를 들어 지금 Kubernetes 버전이 v1.14.x 이면 v1.16.x 로는 업그레이드를 못한다. v1.16.x 로 업그레이드를 하기 위해서는 v1.15.x 로 업그레이드를 하고, v1.16.x 로 다시 업그레이드를 해야 한다.
마침 업그레이드가 필요했고 현재 설치된 Kubernetes 버전이 v1.14.3 이므로 v1.15.6 으로 업그레이드를 먼저 진행하였다.
Every 2.0s: kubectl get nodes Thu Jan 9 16:15:35 2020
NAME STATUS ROLES AGE VERSION
k1-master01 Ready master 323d v1.15.6
k1-master02 Ready master 323d v1.15.6
k1-master03 Ready master 323d v1.15.6
k1-node01 Ready ingress,node 323d v1.14.3
k1-node02 Ready node 323d v1.14.3
k1-node03 Ready node 322d v1.14.3
k1-node04 Ready node 323d v1.14.3
k1-node05 Ready node 323d v1.14.3
이제 Worker 를 업그레이드 할 차례인데, Worker 를 업그레이드는 고려해야 할 사항이 있다. 노드를 업그레이드 하기 위해서는 drain 을 하여 Pod 를 eviction 하는데 Kubespray 는 evction 이 완료될 때 까지 기다린다. DaemonSet 은 무시하는 옵션이 있지만 PodDisruptionBudget 은 policy 에 걸리면 pod 가 terminating 상태에서 완료되지 않기 때문에 timeout 으로 업그레이드에 실패하게 된다. 여기서는 elasticsearch 가 문제가 있어 timeout 나서 실패하였다.
# kubectl get PodDisruptionBudget -A
NAMESPACE NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE
istio-system istio-egressgateway 1 N/A 0 76d
istio-system istio-galley 1 N/A 0 76d
istio-system istio-ingressgateway 1 N/A 0 76d
istio-system istio-pilot 1 N/A 0 76d
istio-system istio-policy 1 N/A 0 76d
istio-system istio-telemetry 1 N/A 0 76d
logging elasticsearch-k1-master-pdb N/A 1 0 71d
elasticsearch 문제를 해결하고 다시 k1-node01 이라는 Worker 노드 1대만 업그레이드를 진행한다.
CNCF 프로젝트 중에 하나로, RBAC 으로 권한에 제한을 두었다고 하더라도 해당 권한의 사용자 컨테이너가 탈취당한다면 컨테이너 안에서 Docker 명령이나 Kubectl 명령으로 새로운 자원을 띄우는 것이 가능하다. 이런 비정상 상황에서 자원 생성을 막을 수 있는 것이 OPA의 gatekeeper 이다.