반응형
2024년 행사 Recap

반응형
쿠버네티스 코리아 디스코드 채널 주소 입니다.
kubernetes-korea Discord 서버에 가입하세요!
Discord에서 kubernetes-korea 커뮤니티를 확인하세요. 395명과 어울리며 무료 음성 및 텍스트 채팅을 즐기세요.
discord.com
$ sudo adduser ask
$ cat <<EOF | sudo tee /etc/sudoers.d/sudoers-ask
ask ALL=(ALL:ALL) NOPASSWD:ALL
EOF
$ sudo systemctl stop ufw
$ sudo systemctl disable ufw
$ sudo systemctl stop apparmor.service
$ sudo systemctl disable apparmor.service
$ sudo swapoff -a
$ cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
$ sudo modprobe overlay
$ sudo modprobe br_netfilter
$ cat <<EOF | sudo tee /etc/sysctl.d/99-kubernetes.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
$ sudo sysctl --system
$ sudo iptables -P FORWARD ACCEPT
$ sudo apt-get update
$ sudo apt-get install -y apt-transport-https ca-certificates curl gpg
$ sudo install -m 0755 -d /etc/apt/keyrings
$ sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
$ sudo chmod a+r /etc/apt/keyrings/docker.asc
$ echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
$ sudo apt-get update
$ sudo apt-get install -y containerd.io
$ sudo mkdir -p /etc/containerd
$ sudo containerd config default | sudo tee /etc/containerd/config.toml
$ sudo sed -i 's/SystemdCgroup \= false/SystemdCgroup \= true/g' /etc/containerd/config.toml
$ sudo systemctl restart containerd
$ sudo systemctl enable containerd
$ sudo systemctl status containerd
#----------------------------------------------------------
# 서버가 arm64 or amd64 인지 확인하여 설치
#----------------------------------------------------------
$ VERSION="v1.30.0"
$ curl -L https://github.com/kubernetes-sigs/cri-tools/releases/download/$VERSION/crictl-${VERSION}-linux-arm64.tar.gz --output crictl-${VERSION}-linux-arm64.tar.gz
$ sudo tar zxvf crictl-$VERSION-linux-arm64.tar.gz -C /usr/local/bin
$ rm -f crictl-$VERSION-linux-arm64.tar.gz
#----------------------------------------------------------
# crictl 이 어느 container 를 접속할 것인지 세팅
#----------------------------------------------------------
$ cat <<EOF | sudo tee /etc/crictl.yaml
runtime-endpoint: unix:///run/containerd/containerd.sock
image-endpoint: unix:///run/containerd/containerd.sock
timeout: 2
debug: false
pull-image-on-create: false
EOF
$ sudo bash -c "crictl completion > /etc/bash_completion.d/crictl"
$ source ~/.bashrc
#----------------------------------------------------------
# containerd 설정 확인
#----------------------------------------------------------
$ sudo crictl info
#----------------------------------------------------------
# 서버가 arm64 or amd64 인지 확인하여 설치
#----------------------------------------------------------
$ curl -LO "https://dl.k8s.io/release/v1.30.0/bin/linux/arm64/kubectl"
$ chmod +x ./kubectl
$ sudo mv ./kubectl /usr/local/bin/kubectl
$ mkdir -p ~/kubeadm && cd ~/kubeadm
#-----------------------------------------------
# kubernetes 다운로드 key 와 url 등록
#-----------------------------------------------
$ curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.30/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
$ echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.30/deb/ /' | sudo tee /etc/apt/sources.list.d/kubernetes.list
$ sudo apt-get update
#========================================================================
# kubelet 설치 (아직 kubelet 이 뜨지는 않음)
#========================================================================
$ sudo apt-get install -y kubelet="1.30.3-*" kubeadm="1.30.3-*"
$ sudo systemctl enable --now kubelet
$ sudo systemctl start kubelet
#========================================================================
# 1. kubeadm 설치
#========================================================================
$ sudo kubeadm config images pull
#------------------------------------------------------------
# 자기 노드의 ip: --apiserver-advertise-address
# multi control-plane 일 경우 L4 ip: --control-plane-endpoint
# cgroup driver 세팅 (https://kubernetes.io/docs/tasks/administer-cluster/kubeadm/configure-cgroup-driver/)
#------------------------------------------------------------
$ vi kubeadm-config.yaml
apiVersion: kubeadm.k8s.io/v1beta3
kind: InitConfiguration
nodeRegistration:
criSocket: "/var/run/containerd/containerd.sock"
---
apiVersion: kubeadm.k8s.io/v1beta3
kind: ClusterConfiguration
apiServer:
certSANs:
- 127.0.0.1
- localhost
- <Node private IP>
- <Node public IP>
networking:
serviceSubnet: 10.233.0.0/18
podSubnet: 10.233.64.0/18
dnsDomain: "cluster.local"
#----------------------------------------------------------------
# kubeadm init 을 하고 나면 /var/lib/kubelet/config.yaml 이 생성되어
# kubelet 이 정상적으로 실행됨
#----------------------------------------------------------------
$ sudo kubeadm init --config kubeadm-config.yaml --v=5
#------------------------------------------------------------
# kubeconfig
#------------------------------------------------------------
$ mkdir -p ~/.kube
$ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
$ sudo chown $(id -u):$(id -g) $HOME/.kube/config
$ mkdir -p ~/calico && cd ~/calico
$ curl -LO https://raw.githubusercontent.com/projectcalico/calico/v3.28.0/manifests/tigera-operator.yaml
$ kubectl create -f tigera-operator.yaml
$ curl -LO https://raw.githubusercontent.com/projectcalico/calico/v3.28.0/manifests/custom-resources.yaml
#------------------------------------------------------------
# yaml 을 열어서 pod 네트워크를 확인하고 변경
#------------------------------------------------------------
$ vi custom-resources.yaml
...
cidr: 10.233.64.0/18
...
$ kubectl create -f custom-resources.yaml
#------------------------------------------------------------
# calico 설치 확인
#------------------------------------------------------------
$ kubectl get pods -n calico-system
$ source <(kubectl completion bash)
$ kubectl completion bash > ~/.kube/completion.bash.inc
$ printf "
# kubectl shell completion
source '$HOME/.kube/completion.bash.inc'
" >> $HOME/.bash_aliases
$ source $HOME/.bash_aliases
$ kubectl taint nodes --all node-role.kubernetes.io/control-plane-
$ mkdir -p ~/sample-yaml && cd ~/sample-yaml
$ cat <<EOF | tee ./nginx-service.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx-deployment
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.21.0
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx-service-nodeport
spec:
selector:
app: nginx
ports:
- protocol: TCP
port: 8080
targetPort: 80
nodePort: 30180
type: NodePort
externalTrafficPolicy: Local
EOF
$ kubectl apply -f nginx-service.yaml
$ kubectl get pods
$ curl <Node ip>:30180minkube 설치는 아래 사이트를 참고한다.
https://minikube.sigs.k8s.io/docs/start/
$ curl -LO <https://storage.googleapis.com/minikube/releases/latest/minikube-darwin-arm64>
$ install minikube-darwin-arm64 /Users/ask/bin/minikube
https://minikube.sigs.k8s.io/docs/drivers/docker/
driver 를 docker 로 사용하기 때문에 docker 를 미리 설치해 놓아야 한다.
$ docker context use default
이후에 minikube 로 cluster 를 생성한다.
$ minikube start --driver=docker --memory=4096
--- output ---
😄 Darwin 13.5.2 (arm64) 의 minikube v1.33.0
✨ 유저 환경 설정 정보에 기반하여 docker 드라이버를 사용하는 중
📌 Using Docker Desktop driver with root privileges
👍 Starting "minikube" primary control-plane node in "minikube" cluster
🚜 Pulling base image v0.0.43 ...
🔥 Creating docker container (CPUs=2, Memory=4096MB) ...
❗ This container is having trouble accessing <https://registry.k8s.io>
💡 To pull new external images, you may need to configure a proxy: <https://minikube.sigs.k8s.io/docs/reference/networking/proxy/>
🐳 쿠버네티스 v1.30.0 을 Docker 26.0.1 런타임으로 설치하는 중
▪ 인증서 및 키를 생성하는 중 ...
▪ 컨트롤 플레인을 부팅하는 중 ...
▪ RBAC 규칙을 구성하는 중 ...
🔗 bridge CNI (Container Networking Interface) 를 구성하는 중 ...
🔎 Kubernetes 구성 요소를 확인...
▪ Using image gcr.io/k8s-minikube/storage-provisioner:v5
🌟 애드온 활성화 : storage-provisioner, default-storageclass
❗ /Users/ask/bin/kubectl is version 1.28.2, which may have incompatibilities with Kubernetes 1.30.0.
▪ Want kubectl v1.30.0? Try 'minikube kubectl -- get pods -A'
🏄 끝났습니다! kubectl이 "minikube" 클러스터와 "default" 네임스페이스를 기본적으로 사용하도록 구성되었습니다.
디폴트 메모리를 config 에 세팅할 수 도 있다.
config 세팅은 기존에 만든 minikube node 에는 적용이 안되고 새롭게 만드는 노드에만 적용된다.
$ minikube config set memory 4096
minikube 에 worker node 를 추가할 수 있다.
$ minikube node add
node 가 추가된 것을 볼 수 있다.
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
minikube Ready control-plane 8m22s v1.30.0
minikube-m02 Ready <none> 86s v1.30.0
node 에 Role 을 추가하고 싶으면 다음과 같이 지정한다.
$ kubectl label node minikube-m02 node-role.kubernetes.io/node=enabled --overwrite
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
minikube Ready control-plane 15m v1.30.0
minikube-m02 Ready node 8m12s v1.30.0
$ minkube status
--- output ---
minikube
type: Control Plane
host: Running
kubelet: Running
apiserver: Running
kubeconfig: Configured
minikube-m02
type: Worker
host: Running
kubelet: Running
$ minkube pause -A
--- output --
⏸️ Pausing node minikube ...
⏸️ Pausing node m02 ...
⏯️ Paused 16 containers
$ minikube unpause -A
--- output ---
⏸️ Unpausing node minikube ...
⏸️ Unpausing node m02 ...
⏸️ Unpaused 16 containers
$ minikube stop --all=true
--- output ---
✋ "minikube-m02" 노드를 중지하는 중 ...
🛑 "minikube-m02"를 SSH로 전원을 끕니다 ...
✋ "minikube" 노드를 중지하는 중 ...
🛑 "minikube"를 SSH로 전원을 끕니다 ...
🛑 2개의 노드가 중지되었습니다.
$ minikube start -p aged --kubernetes-version=v1.28.2
minikube delete --all
$ minikube addons list
|-----------------------------|----------|--------------|--------------------------------|
| ADDON NAME | PROFILE | STATUS | MAINTAINER |
|-----------------------------|----------|--------------|--------------------------------|
| ambassador | minikube | disabled | 3rd party (Ambassador) |
| auto-pause | minikube | disabled | minikube |
| cloud-spanner | minikube | disabled | Google |
| csi-hostpath-driver | minikube | disabled | Kubernetes |
| dashboard | minikube | disabled | Kubernetes |
| default-storageclass | minikube | enabled ✅ | Kubernetes |
| efk | minikube | disabled | 3rd party (Elastic) |
| freshpod | minikube | disabled | Google |
| gcp-auth | minikube | disabled | Google |
| gvisor | minikube | disabled | minikube |
| headlamp | minikube | disabled | 3rd party (kinvolk.io) |
| helm-tiller | minikube | disabled | 3rd party (Helm) |
| inaccel | minikube | disabled | 3rd party (InAccel |
| | | | [info@inaccel.com]) |
| ingress | minikube | disabled | Kubernetes |
| ingress-dns | minikube | disabled | minikube |
| inspektor-gadget | minikube | disabled | 3rd party |
| | | | (inspektor-gadget.io) |
| istio | minikube | disabled | 3rd party (Istio) |
| istio-provisioner | minikube | disabled | 3rd party (Istio) |
| kong | minikube | disabled | 3rd party (Kong HQ) |
| kubeflow | minikube | disabled | 3rd party |
| kubevirt | minikube | disabled | 3rd party (KubeVirt) |
| logviewer | minikube | disabled | 3rd party (unknown) |
| metallb | minikube | disabled | 3rd party (MetalLB) |
| metrics-server | minikube | disabled | Kubernetes |
| nvidia-device-plugin | minikube | disabled | 3rd party (NVIDIA) |
| nvidia-driver-installer | minikube | disabled | 3rd party (Nvidia) |
| nvidia-gpu-device-plugin | minikube | disabled | 3rd party (Nvidia) |
| olm | minikube | disabled | 3rd party (Operator Framework) |
| pod-security-policy | minikube | disabled | 3rd party (unknown) |
| portainer | minikube | disabled | 3rd party (Portainer.io) |
| registry | minikube | disabled | minikube |
| registry-aliases | minikube | disabled | 3rd party (unknown) |
| registry-creds | minikube | disabled | 3rd party (UPMC Enterprises) |
| storage-provisioner | minikube | enabled ✅ | minikube |
| storage-provisioner-gluster | minikube | disabled | 3rd party (Gluster) |
| storage-provisioner-rancher | minikube | disabled | 3rd party (Rancher) |
| volumesnapshots | minikube | disabled | Kubernetes |
| yakd | minikube | disabled | 3rd party (marcnuri.com) |
|-----------------------------|----------|--------------|--------------------------------|
$ minikube addons enable dashboard
--- output ---
💡 dashboard is an addon maintained by Kubernetes. For any concerns contact minikube on GitHub.
You can view the list of minikube maintainers at: <https://github.com/kubernetes/minikube/blob/master/OWNERS>
▪ Using image docker.io/kubernetesui/dashboard:v2.7.0
▪ Using image docker.io/kubernetesui/metrics-scraper:v1.0.8
💡 Some dashboard features require the metrics-server addon. To enable all features please run:
minikube addons enable metrics-server
🌟 'dashboard' 애드온이 활성화되었습니다
$ minikube addons enable metrics-server
--- output ---
💡 metrics-server is an addon maintained by Kubernetes. For any concerns contact minikube on GitHub.
You can view the list of minikube maintainers at: <https://github.com/kubernetes/minikube/blob/master/OWNERS>
▪ Using image registry.k8s.io/metrics-server/metrics-server:v0.7.1
🌟 'metrics-server' 애드온이 활성화되었습니다
$ minikube dashboard --url
minikube 를 설치하고 pod 가 생성안되는 가장 큰 이유는 proxy 때문이다. 회사에서 proxy 를 사용한다면 proxy 세팅을 추가로 해줘야 한다.
아래 내용은 proxy 이외의 문제일 때 해결 방법이다.
Error response from daemon: Get "<https://registry-1.docker.io/v2/>": tls: failed to verify certificate: x509: certificate signed by unknown authority
minikube 의 docker-env 를 확인한 후 세팅한다.
$ minikube -p minikube docker-env
--- output ---
export DOCKER_TLS_VERIFY="1"
export DOCKER_HOST="tcp://127.0.0.1:53131"
export DOCKER_CERT_PATH="/Users/ask/.minikube/certs"
export MINIKUBE_ACTIVE_DOCKERD="minikube"
$ docker context create minikube --description "Minikube" --docker "host=tcp://localhost:53131,ca=/Users/ask/.minikube/certs/ca.pem,cert=/Users/ask/.minikube/certs/cert.pem,key=/Users/ask/.minikube/certs/key.pem"
$ docker context use minikube
위의 경우에는 minikube 를 띄울 때 --insecure-registry 를 추가한다.
$ minikube start --insecure-registry="registry-1.docker.io"
아니면 minikube 로 노드에 접속해서 docker 에 인증서를 추가한다.
$ minikube ssh
$ sudo su -
$ update-ca-certificates --fresh
$ openssl s_client -showcerts -verify 5 -connect k8s.gcr.io:443 < /dev/null 2>/dev/null | openssl x509 -outform PEM | tee ~/k8s.gcr.io.crt
$ openssl s_client -showcerts -verify 5 -connect registry-1.docker.io:443 < /dev/null 2>/dev/null | openssl x509 -outform PEM | tee ~/registry-1.docker.io.crt
$ openssl s_client -showcerts -verify 5 -connect auth.docker.io:443 < /dev/null 2>/dev/null | openssl x509 -outform PEM | tee ~/auth.docker.io.crt
$ cp ~/k8s.gcr.io.crt /usr/local/share/ca-certificates/
$ cp ~/registry-1.docker.io.crt /usr/local/share/ca-certificates/
$ cp ~/auth.docker.io.crt /usr/local/share/ca-certificates/
$ update-ca-certificates
$ systemctl restart docker
kind 는 아래 설치 사이트를 참조한다.
https://kind.sigs.k8s.io/docs/user/quick-start/
$ [ $(uname -m) = arm64 ] && curl -Lo ./kind <https://kind.sigs.k8s.io/dl/v0.22.0/kind-darwin-arm64>
$ chmod +x kind
$ mv kind ~/bin/kind
image 는 아래 사이트에서 확인 가능하다.
https://github.com/kubernetes-sigs/kind/releases
kind config 는 여기를 참조한다.
https://kind.sigs.k8s.io/docs/user/quick-start/#configuring-your-kind-cluster
ingress 를 사용하기 위해서는 아래 내용 처럼 port mapping 을 해야 한다.
https://kind.sigs.k8s.io/docs/user/ingress
$ vi kind-config.yaml
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
# patch the generated kubeadm config with some extra settings
kubeadmConfigPatches:
- |
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
evictionHard:
nodefs.available: "0%"
# patch it further using a JSON 6902 patch
kubeadmConfigPatchesJSON6902:
- group: kubeadm.k8s.io
version: v1beta3
kind: ClusterConfiguration
patch: |
- op: add
path: /apiServer/certSANs/-
value: my-hostname
nodes:
- role: control-plane
image: kindest/node:v1.29.2@sha256:51a1434a5397193442f0be2a297b488b6c919ce8a3931be0ce822606ea5ca245
# extraPortMappings:
# - containerPort: 80
# hostPort: 10080
# listenAddress: "0.0.0.0" # Optional, defaults to "0.0.0.0"
# protocol: tcp # Optional, defaults to tcp
- role: worker
image: kindest/node:v1.29.2@sha256:51a1434a5397193442f0be2a297b488b6c919ce8a3931be0ce822606ea5ca245
#featureGates:
# FeatureGateName: true
$ KIND_EXPERIMENTAL_PROVIDER=docker && kind create cluster --name kind --config kind-config.yaml
--- output ---
Creating cluster "kind" ...
✓ Ensuring node image (kindest/node:v1.29.2) 🖼
✓ Preparing nodes 📦 📦
✓ Writing configuration 📜
✓ Starting control-plane 🕹️
✓ Installing CNI 🔌
✓ Installing StorageClass 💾
✓ Joining worker nodes 🚜
Set kubectl context to "kind-kind"
You can now use your cluster with:
kubectl cluster-info --context kind-kind
Thanks for using kind! 😊
$ kind get clusters
$ kubectl cluster-info --context kind-kind
$ kind delete cluster --name kind
스터디에서 준비해야 할 내용 리스트
Kubernetes 를 세미나를 하거나 모임에서 만나면 쿠버네티스를 알고 싶어 하시는 분들이 제일 문제 물어보는 것이 있다.
"쿠버네티스를 잘 모르는데 이제부터 공부하고 싶어요. 어떤거 부터 하면 좋을까요?"
그 동안은 이는 리눅스를 무엇부터 공부해야 할까요? 와 거의 비슷한 이야기인거 같다. 그래서 키워드로 스스로 공부할 수 있도록 키워드로 리스트를 만들었다.
helm chart 를 만들기 위해서는 여러 기능들을 알아야 하지만 그 중에서 가장 많이 쓰고 헷갈리는 기능에 대해서 살펴 본다.
기본적으로 실습할 수 있는 환경을 먼저 만들고 하나씩 공부해 본다.
$ helm create flow-control
$ cd flow-controlyaml 형태의 출력을 확인해 본다.
$ helm template .
---
# Source: flow-control/templates/serviceaccount.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: release-name-flow-control
labels:
helm.sh/chart: flow-control-0.1.0
app.kubernetes.io/name: flow-control
app.kubernetes.io/instance: release-name
app.kubernetes.io/version: "1.16.0"
app.kubernetes.io/managed-by: Helm
automountServiceAccountToken: true
---
# Source: flow-control/templates/service.yaml
apiVersion: v1
kind: Service
metadata:
name: release-name-flow-control
labels:
helm.sh/chart: flow-control-0.1.0
app.kubernetes.io/name: flow-control
app.kubernetes.io/instance: release-name
app.kubernetes.io/version: "1.16.0"
app.kubernetes.io/managed-by: Helm
spec:
type: ClusterIP
ports:
- port: 80
targetPort: http
protocol: TCP
name: http
selector:
app.kubernetes.io/name: flow-control
app.kubernetes.io/instance: release-name
---
# Source: flow-control/templates/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: release-name-flow-control
labels:
helm.sh/chart: flow-control-0.1.0
app.kubernetes.io/name: flow-control
app.kubernetes.io/instance: release-name
app.kubernetes.io/version: "1.16.0"
app.kubernetes.io/managed-by: Helm
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/name: flow-control
app.kubernetes.io/instance: release-name
template:
metadata:
labels:
helm.sh/chart: flow-control-0.1.0
app.kubernetes.io/name: flow-control
app.kubernetes.io/instance: release-name
app.kubernetes.io/version: "1.16.0"
app.kubernetes.io/managed-by: Helm
spec:
serviceAccountName: release-name-flow-control
securityContext:
{}
containers:
- name: flow-control
securityContext:
{}
image: "nginx:1.16.0"
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
protocol: TCP
livenessProbe:
httpGet:
path: /
port: http
readinessProbe:
httpGet:
path: /
port: http
resources:
{}
---
# Source: flow-control/templates/tests/test-connection.yaml
apiVersion: v1
kind: Pod
metadata:
name: "release-name-flow-control-test-connection"
labels:
helm.sh/chart: flow-control-0.1.0
app.kubernetes.io/name: flow-control
app.kubernetes.io/instance: release-name
app.kubernetes.io/version: "1.16.0"
app.kubernetes.io/managed-by: Helm
annotations:
"helm.sh/hook": test
spec:
containers:
- name: wget
image: busybox
command: ['wget']
args: ['release-name-flow-control:80']
restartPolicy: Never제대로 출력된다면 필요없는 파일은 삭제하고 초기화 하자.
$ rm -rf template/*
$ cat /dev/null > values.yaml가장 간단한 configmap 을 만들어서 value 값을 출력한다.
$ values.yaml
---
favorite:
drink: coffee
food: pizza
$ vi template/configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: {{ .Release.Name }}-configmap
data:
myvalue: "Hello World"
drink: {{ .Values.favorite.drink | default "tea" | quote }}
food: {{ .Values.favorite.food | upper | quote }}
{{ if eq .Values.favorite.drink "coffee" }}
mug: "true"
{{ end }}
$ helm template .
--- output ---
Error: YAML parse error on flow-control/templates/configmap.yaml: error converting YAML to JSON: yaml: line 8: did not find expected key
Use --debug flag to render out invalid YAMLtemplate 을 제너레이션하면 에러가 발생한다. 왜 그럴까?
configmap.yaml 에 mug: "true" 가 2칸 들여써 있어서 발생하는 에러이다. 이런 에러를 조심하면서 아래 실습을 해보자.
configmap.yaml 을 수정해서 제대로 yaml 을 생성해 보자.
$ vi template/configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: {{ .Release.Name }}-configmap
data:
myvalue: "Hello World"
drink: {{ .Values.favorite.drink | default "tea" | quote }}
food: {{ .Values.favorite.food | upper | quote }}
{{ if eq .Values.favorite.drink "coffee" }}
mug: "true"
{{ end }}
$ helm template .
---
# Source: flow-control/templates/configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: release-name-configmap
data:
myvalue: "Hello World"
drink: "coffee"
food: "PIZZA"
--------------> 빈라인 발생한다.
mug: "true"
--------------> 빈라인 발생한다..Release.Name 은 helm 으로 설치할 때 파라미터로 넘기는 값인데 여기서는 설치가 아니므로 기본 값인 release-name 으로 치환 되었고, .Values.favorite.drink 는 values.yaml 에 지정한 키값으로 그에 해당하는 밸류 값이 제너레이트 될 때 출력된다.
함수의 연속적 사용은 | 라인으로 호출 가능하며 default 는 키에 대한 값이 없을 때, quote 는 값을 " 으로 묶을 때 upper 는 값을 대문자로 변환할 때 사용하는 내장 함수이다.
비교 구문은 if eq 값1 값2 와 같이 사용할 수 있다.
출력하지 않는 곳에서는 빈라인이 발생하는데 이 부분을 다음과 같이 없애 줄 수 있다.
{{ if eq .Values.favorite.drink "coffee" }}mug: "true"{{ end }}하지만 가독성이 떨어지므로 {{- 와 같이 표현하면 빈라인이 없어지면서 윗라인에 나란히 붙는 것과 같은 효과를 낼 수 있다.
{{- if eq .Values.favorite.drink "coffee" }}
mug: "true"
{{- end }}다시 yaml 을 생성해 보면 아래와 같이 빈라인이 없어졌음을 알 수 있다.
$ helm template .
---
# Source: flow-control/templates/configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: release-name-configmap
data:
myvalue: "Hello World"
drink: "coffee"
food: "PIZZA"
mug: "true"조건문 대신 다음과 같이 with 를 사용하여 조건문과 키밸류 스쿱을 지정할 수 있다.
### configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: {{ .Release.Name }}-configmap
data:
myvalue: "Hello World"
{{- with .Values.hobby }}
sports: {{ .sports }}
{{- end }}
### values.yaml
hobby:
sports: golfwith 와 함께 사용한 키는 해당 키에 대한 값이 있을 때만 with ~ end 로 감싼 구문이 출력된다. 또한 감싼 구문 안에서는 스쿱이 재정의되어 hobby 아래의 키인 sports 를 .sports 로 바로 사용할 수 있다.
yaml 을 생성하면 다음과 같은 결과가 나온다.
$ helm template .
# Source: flow-control/templates/configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: release-name-configmap
data:
myvalue: "Hello World"
sports: golf만약 values 에 sports 를 없애면 아래와 같이 출력되지 않는다.
### values.yaml
hobby: {}
# Source: flow-control/templates/configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: release-name-configmap
data:
myvalue: "Hello World"hobby 아래의 키는 키밸류인 디셔너리 타입을 넣기 때문에 아래의 값을 모두 없애기 위해서{} 빈 딕셔너리 값으로 지정했다. 만약 아래의 값이 리스트라면 [] 와 같이 빈 리스트 값을 지정할 수 있다.
with ~ end 로 감싼 구문에서 root 영역의 value 를 활용하고 싶을 수 있다. 이 때는 $ 를 붙혀서 영역을 최상위 root 로 접근할 수 있다. 아래 예제에서 $.Release.Name 을 참고한다.
### configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: {{ .Release.Name }}-configmap
data:
myvalue: "Hello World"
{{- with .Values.hobby }}
sports: {{ .sports }}
release: {{ $.Release.Name }}
{{- end }}YAML 은 JSON 의 수퍼셋이기 때문에 JSON 으로 표현하여 가독성을 높혀줄 수 도 있다. pod 를 만들 때 yaml 에 args 를 추가할 수 있는데. 이 때 JSON 을 쓰면 읽기에 편하다.
args:
- "--dirname"
- "/foo" 위의 내용은 JSON 으로 아래와 같이 바꿀 수 있다.
args: ["--dirname", "/foo"]range 를 이용하여 반복문을 사용할 수 있다.
### values.yaml
pizzaToppings:
- mushrooms
- cheese
- peppers
- onions
### configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: {{ .Release.Name }}-configmap
data:
toppings: |-
{{- range .Values.pizzaToppings }}
- {{ . | title | quote }}
{{- end }}pizzaToppings 의 값은 리스트이다(- 기호가 값으로 붙었기 때문에 리스트임을 알 수 있다). 리스트로 값을 가져와서 출력하기 때문에 아래와 같은 결과가 나온다.
# Source: flow-control/templates/configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: release-name-configmap
data:
toppings: |-
- "Mushrooms"
- "Cheese"
- "Peppers"
- "Onions"한가지 yaml 에서 toppings: 의 뒤에 따라온 |- 기호의 의미는 멀티 라인 스트링을 받겠다는 의미이다.
tuple 을 사용하여 튜플로 만들어 쓸 수 도 있다.
### configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: {{ .Release.Name }}-configmap
data:
sizes: |-
{{- range tuple "small" "medium" "large" }}
- {{ . }}
{{- end }}
### 출력 결과
# Source: flow-control/templates/configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: release-name-configmap
data:
sizes: |-
- small
- medium
- large$ 와 := 를 이용하여 변수를 지정할 수 있다. 아래는 리스트에서 받은 값을 index 변수와 value 변수로 받아서 활용하는 부분이다.
### values.yaml
pizzaToppings:
- mushrooms
- cheese
- peppers
- onions
### configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: {{ .Release.Name }}-configmap
data:
toppings: |-
{{- range $index, $value := .Values.pizzaToppings }}
- {{ $index }}: {{ $value }}
{{- end }}
# Source: flow-control/templates/configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: release-name-configmap
data:
toppings: |-
- 0: mushrooms
- 1: cheese
- 2: peppers
- 3: onionsmap 값을 변수로 받아 처리할 수 도 있다.
### values.yaml
favorite:
drink: coffee
food: pizza
### configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: {{ .Release.Name }}-configmap
data:
favorite: |-
{{- range $key, $value := .Values.favorite }}
{{ $key }}: {{ $value }}
{{- end }}
# Source: flow-control/templates/configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: release-name-configmap
data:
favorite: |-
drink: coffee
food: pizza부분적으로 사용자 정의 template 을 만들어서 활용 할 수 있다.
template 은 define 으로 선언하고 tempate 으로 활용할 수 있다.
### configmap.yaml
{{- define "mychart.labels" }}
labels:
generator: helm
date: {{ now | htmlDate }}
{{- end }}
apiVersion: v1
kind: ConfigMap
metadata:
name: {{ .Release.Name }}-configmap
{{- template "mychart.labels" }}
data:
myvalue: "Hello World"
# Source: flow-control/templates/configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: release-name-configmap
labels:
generator: helm
date: 2023-10-31
data:
myvalue: "Hello World"위의 예제는 labels 에 date: 날짜 를 추가로 넣는 부분을 named template 을 만들어서 사용한 예제이다.
chat 를 만들 때 configmap.yaml 과 같이 쿠버네티스 리소스들은 template 디렉토리 아래에 위치 시킨다고 했다. 이 디렉토리에 위치한 yaml 파일들은 자동으로 렌더링에 포함되는데 _ 로 시작하는 파일은 렌더링에서 제외한다. 그래서 보통 define 으로 정의한 함수들은 _helper.tpl 파일을 만들어서 이곳에 위치 시킨다.
define 으로 정의된 named template (함수) 은 template 으로 호출되기 전까지는 렌더링 되지 않는다. 이제 이 함수를 _helper.tpl 파일로 옮겨서 렌더링 결과를 살펴보자.
# _helper.tpl
{{- define "mychart.labels" }}
labels:
generator: helm
date: {{ now | htmlDate }}
{{- end }}
# configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: {{ .Release.Name }}-configmap
{{- template "mychart.labels" }}
data:
myvalue: "Hello World"
# Source: flow-control/templates/configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: release-name-configmap
labels:
generator: helm
date: 2023-10-31
data:
myvalue: "Hello World"위의 예제에서 define 함수 내에서 .Values 와 같이 value 를 가져오는 것은 하지 않았다. 아래와 같이 {{ .Chart.Name }} 을 사용한다면 위의 방식으로는 값을 표현할 수 없다.
# _helper.tpl
{{- define "mychart.labels" }}
labels:
generator: helm
date: {{ now | htmlDate }}
chart: {{ .Chart.Name }}
version: {{ .Chart.Version }}
{{- end }}
# Source: flow-control/templates/configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: release-name-configmap
labels:
generator: helm
date: 2023-10-31
chart:
version:
data:
myvalue: "Hello World"이는 template 으로 호출할 때 뒤에 value 를 보내지 않아서 발생한 부분이다. 즉 {{- template "mychart.labels" . }} 과 같이 마지막에 현재의 scope value 인 . 을 넘겨 주어야 제대로 된 값이 출력된다.
# configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: {{ .Release.Name }}-configmap
{{- template "mychart.labels" . }}
data:
myvalue: "Hello World"
# Source: flow-control/templates/configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: release-name-configmap
labels:
generator: helm
date: 2023-10-31
chart: flow-control
version: 0.1.0template 은 있는 그대로 output 을 보여주기 때문에 들여쓰기의 문제가 있을 수 있다.
# _helper.tlp
{{- define "mychart.app" -}}
app_name: {{ .Chart.Name }}
app_version: "{{ .Chart.Version }}"
{{- end -}}
# configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: {{ .Release.Name }}-configmap
labels:
{{ template "mychart.app" . }}
data:
myvalue: "Hello World"
{{ template "mychart.app" . }}
# Source: flow-control/templates/configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: release-name-configmap
labels:
app_name: flow-control
app_version: "0.1.0"
data:
myvalue: "Hello World"
app_name: flow-control
app_version: "0.1.0"app_name 과 app_version 이 출력된 것을 보면 define 에 정의된 들여쓰기 대로 그대로 출력되어 원하는 대로 출력되지 않는다.
include 와 nindent 를 사용하면 원하는 들여쓰기가 가능하다.
# configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: {{ .Release.Name }}-configmap
labels:
{{ template "mychart.app" . }}
data:
myvalue: "Hello World"
{{ template "mychart.app" . }}
# Source: flow-control/templates/configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: release-name-configmap
labels:
app_name: flow-control
app_version: "0.1.0"
data:
myvalue: "Hello World"
app_name: flow-control
app_version: "0.1.0"끝으로 helm install 할 때 들여쓰기가 잘못되면 렌더링 오류가 나서 최종 결과를 볼 수 가 없다. 이를 해결할 수 있는 옵션이 -disable-openapi-validation 이다.
$ helm install --dry-run --disable-openapi-validation mychart ./Kubernetes 에서 ServiceAccount 를 생성하면 1.22 버전까지는 자동으로 token 을 생성하였다. 그러나 1.23 부터는 토큰을 자동으로 생성해 주지 않기 때문에 수동으로 생성해야 한다.
이 바뀐 기능은 ServiceAcount 와 RBAC 을 연동하여 권한을 제어하고자 할 때 문제가 되므로 수동으로 만드는 방법을 살펴본다.
먼저 테스트할 네임스페이스를 만든다.
$ kubectl create ns askask 네임스페이스에 서비스 어카운트를 생성한다.
$ kubectl create sa ask-sa -n ask1.24 버전부터는 sa 를 생성해도 token 이 자동으로 생성되지 않는다.
token 은 Secret 타입이므로 Secret 을 조회해 보면 token이 자동 생성되지 않았음을 알 수 있다.
참고: https://kubernetes.io/docs/concepts/configuration/secret/#service-account-token-secrets
ask-sa 에 해당하는 token 을 수동으로 생성한다.
$ cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Secret
metadata:
name: ask-sa
namespace: ask
annotations:
kubernetes.io/service-account.name: ask-sa
type: kubernetes.io/service-account-token
EOFtoken 을 생성할 때 어노테이션으로 연결될 서비스 어카운트를 지정한다.
$ kubectl get secret -n ask
NAME TYPE DATA AGE
ask-sa kubernetes.io/service-account-token 3 7s 조회를 하면 service-account-toke 타입으로 secret 이 생성되었음을 알 수 있다.
혹은 token 을 수동으로 생성하는 방법도 있다.
$ kubectl create token ask-sa --bound-object-kind Secret --bound-object-name ask-sa --duration=999999h -n ask
------- output -----------
xxxxxxxxxxxxxxxxxxxxxxxbase64 로 변환하여 secret 에 data.token 값으로 저장한다.
$ kubectl create token ask-sa --bound-object-kind Secret --bound-object-name ask-sa --duration=999999h -n ask | base64 -w 0
------- output -----------
xxxxxxxxxxxxxxxxxxxxxxx$ kubectl edit secret ask-sa -n ask
...
data:
token: xxxxxxxxxxxxxxxxxxxx
...Role 과 RoleBinding 은 네임스페이스 별로 연결된다. 그러므로 생성한 권한은 해당 네임스페이스에만 권한이 주어진다.
먼저 Role 을 생성한다.
$ cat <<EOF | kubectl apply -f -
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: ask-role
namespace: ask
rules:
- apiGroups: ["", "*"]
resources: ["*"]
verbs: ["*"]
EOFapiGroup 에서 "" 은 core API group 으로 다음의 출력으로 확인할 수 있다.
APIVERSION 이 v1 인 리소스들이 core API group 이 되면 이들에 대해서 권한을 사용하겠다는 뜻이다.
$ kubectl api-resources -o wide
NAME SHORTNAMES APIVERSION NAMESPACED KIND VERBS
bindings v1 true Binding [create]
componentstatuses cs v1 false ComponentStatus [get list]
configmaps cm v1 true ConfigMap [create delete deletecollection get list patch update watch]
endpoints ep v1 true Endpoints [create delete deletecollection get list patch update watch]
events ev v1 true Event [create delete deletecollection get list patch update watch]
limitranges limits v1 true LimitRange [create delete deletecollection get list patch update watch]
namespaces ns v1 false Namespace [create delete get list patch update watch]
nodes no v1 false Node [create delete deletecollection get list patch update watch]
persistentvolumeclaims pvc v1 true PersistentVolumeClaim [create delete deletecollection get list patch update watch]
persistentvolumes pv v1 false PersistentVolume [create delete deletecollection get list patch update watch]
pods po v1 true Pod [create delete deletecollection get list patch update watch]
podtemplates v1 true PodTemplate [create delete deletecollection get list patch update watch]
replicationcontrollers rc v1 true ReplicationController [create delete deletecollection get list patch update watch]
resourcequotas quota v1 true ResourceQuota [create delete deletecollection get list patch update watch]
secrets v1 true Secret [create delete deletecollection get list patch update watch]
serviceaccounts sa v1 true ServiceAccount [create delete deletecollection get list patch update watch]
services svc v1 true Service [create delete deletecollection get list patch update watch]다음은 Rolebinding을 생성한다.
$ cat <<EOF | kubectl apply -f -
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: ask-role-binding
namespace: ask
subjects:
- kind: ServiceAccount
name: ask-sa
namespace: ask
roleRef:
kind: Role
name: ask-role
apiGroup: rbac.authorization.k8s.io
EOFServiceAcount 인 ask-sa 와 ask-role Role 을 서로 연결 시킨 다는 의미이다.
이렇게 되면 이제 ask-sa sa 는 ask-role role 에 대한 권한만을 사용할 수 있다.
sa 를 만들었으니 이를 연동할 kubeconfig 를 만들어 본다.
token 을 조회해 보자.
$ kubectl get secret -n ask ask-sa -ojsonpath={.data.token} | base64 -d
----- output -----
xxxxxxxxxxxxxxxxxxxxxxxxxtoken 값으로 kubeconfig 의 user 접속 token 에 넣는다.
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: xxxxxxxxxxxxxxxxxxxxxxxx
server: https://xxxxxxxxxx.ap-northeast-2.eks.amazonaws.com
name: mycluster
contexts:
- context:
cluster: mycluster
user: ask-sa
namespace: ask
name: mycluster
current-context: mycluster
kind: Config
users:
- name: ask-sa
user:
token: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx위의 kubeconfig 로 접속하면 ask 네임스페이스에 대해서 kubectl 명령어를 실행할 수 있다.
$ kubectl --kubeconfig ask.kubeconfig get pods
Error from server (Forbidden): pods is forbidden: User "system:serviceaccount:ask:ask-sa" cannot list resource "pods" in API group "" in the namespace "default"default 네임스페이스에는 권한이 없으므로 권한 없음 에러가 리턴된다.
$ kubectl --kubeconfig ask.kubeconfig get pods -n ask
No resources found in ask namespace.ask 네임스페이스의 파드는 정상적으로 조회된다.
컨테이너 이미지 저장소를 독립적으로 구성하는 방법을 살펴본다.
일반적으로 컨테이너 이미지는 CNCF 의 프로젝트 중에 하나인 Harbor 를 사용하여 구성한다. Helm chart 가 잘 되어 있어 쿠버네티스 위에서 설치하는 것은 매우 쉬운데 운영 환경에 걸맞는 HA 구성은 여러가지 고려해야 할 사항들이 있다.
그래서 이번에는 Harbor 를 HA 로 구성하는 방법을 알아본다.
Harbor 를 HA 로 구성하려면 아래의 전제 조건이 필요하다.
이 중에서 1, 2, 3 번은 구성되어 있다고 가정하고 이후를 살펴본다.
또한 Public Cloud 는 AWS 를 사용했고 쿠버네티스 클러스터는 EKS 를 사용했다.
아키텍처는 아래 그림과 같다.
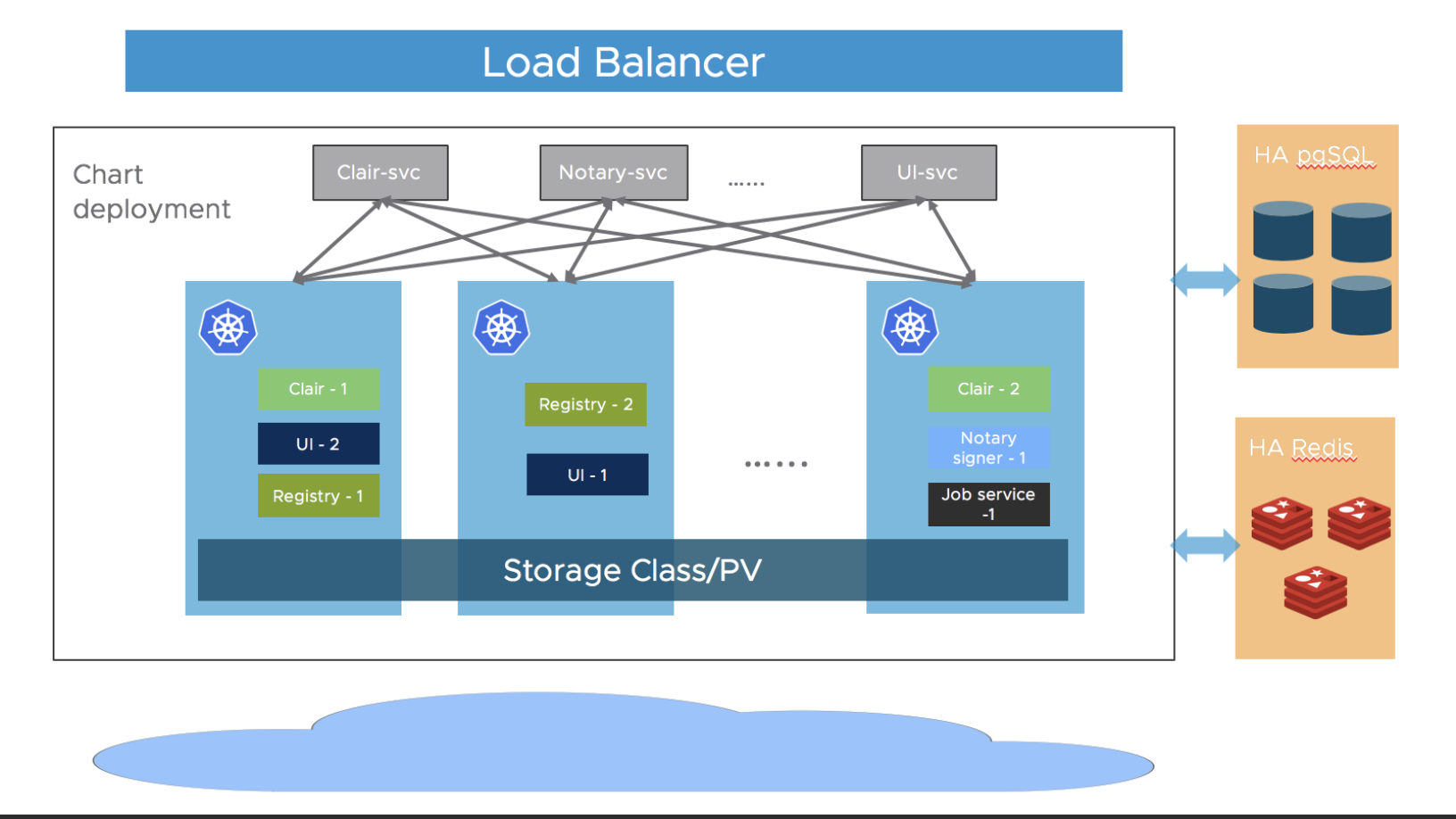
[출처: https://goharbor.io/docs/1.10/img/ha.png]
AWS 의 RDS 를 사용했으며 Harbor 에서 사용할 필요한 user 생성과 권한을 부여한다.
# psql -U postgres
postgres=# CREATE DATABASE registry;
postgres=# CREATE USER harbor WITH ENCRYPTED PASSWORD 'xxxxxxx';
postgres=# GRANT ALL PRIVILEGES ON DATABASE registry TO harbor;어드민 권한으로 데이터베이스에 접속하여 Harbor 에서 사용할 registry database 를 생성한다. user 는 harbor 이고 필요한 password 를 생성한 다음 registry 데이터베이스의 모든 권한을 harbor 유저에 부여한다.
테이블과 스퀀스를 다루기 위해서는 아래 추가적으로 권한을 부여해야 한다. (아래 권한이 추가되지 않으면 harbor 유저로 테이블과 시퀀스에 대한 생성/조회/삭제/수정을 하지 못한다.
postgres=# \c registry
registry=# GRANT ALL ON ALL TABLES IN SCHEMA public TO harbor;
registry=# GRANT ALL ON ALL SEQUENCES IN SCHEMA public TO harbor;Harbor 는 캐시로 레디스를 사용하며 이 때 레디스 구성은 독립 혹은 레디스 + 센티널(sentinel) 구성만을 지원한다. 한마디로 클러스터 모드의 레디스는 지원하지 않는다.
AWS Elasticache Redis 서비스는 센티널을 지원하지 않아 굳이 Elasticache 서비스를 사용할 이유가 없다.
Elasticache 서비스의 레디스 구성으로 1개의 컨트롤노드 - 멀티 워커노드 로 하여 데이터 복제는 가능하나 1개의 컨트롤 노드가 무너지면 역시 장애가 발생하므로 서비스를 사용하여 구성하지 않았다.
이 후 살펴볼 Harbor Helm chart 에서 쿠버네티스 위에 레디스를 1개로 띄우는 internal 생성 방식을 사용한다.
레디스 구성을 HA 로 하고 싶다면, 레디스를 멀티 노드 센티널 구성으로 쿠버네티스 위에 띄우는 방법도 있으니 이는 레디스 설치 문서를 참고하면 된다. (센티널 구성일 때 Harbor chart 의 value 값은 코멘트로 적혀있으니 쉽게 이해할 수 있다)
AWS 에서 지원하는 공유 스토리지는 EFS 가 있다. EFS 는 NFSv4 프로토콜을 지원하니 공유 스토리지로 사용 가능하다.
먼저 AWS EFS 서비스에서 파일스토리지를 생성한다.
생성된 EFS 는 실제로 파일시스템의 스토리지가 생성된 것은 아니다. 일종의 정보를 생성한 것이며 필요에 따라 실제 스토리지를 생성하고 할당 받는 방식이다.
쿠버네티스에서는 Provisioner, StroageClass PVC, PV 라는 스토리지 표준 관리 방법이 있다.

흔히 Provisioner 라고 말하는 CSI Driver 를 설치한다.
EKS 에서는 추가 기능으로 Amazon EFS CSI Driver 를 추가할 수 있다.
이 때 권한에서 중요한 한가지가 있는데 EKS node 에서 사용하는 role 에 (role 명은 eks 의 태그 정보를 확인해 보면 된다) AmazonEFSCSIDriverPolicy 정책이 반드시 추가되어 있어야 한다.
이제 스토리지 클래스를 설치하자.
$ curl -Lo efs-sc.yaml https://raw.githubusercontent.com/kubernetes-sigs/aws-efs-csi-driver/master/examples/kubernetes/dynamic_provisioning/specs/storageclass.yaml
$ vi efs-sc.yaml
---
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: taco-efs-storage
provisioner: efs.csi.aws.com
parameters:
provisioningMode: efs-ap
fileSystemId: fs-xxxxxxx # EFS 에서 생성한 fs id
directoryPerms: "700"
$ kubectl apply -f efs-sc.yaml변경해야 할 것은 fileSystemId 로 앞서 EFS 에서 생성한 파일스토리지의 fs id 값으로 변경해 준다.
스토리지클래스가 잘 작동하는지 확인하기 위해서 아래와 같이 테스트 파드를 생성해 본다.
$ kubectl create ns harbor-ask
$ vi efs-test-pod.yaml
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: efs-claim
namespace: harbor-ask
spec:
accessModes:
- ReadWriteMany
storageClassName: taco-efs-storage
resources:
requests:
storage: 5Gi
---
apiVersion: v1
kind: Pod
metadata:
name: efs-app
namespace: harbor-ask
spec:
containers:
- name: app
image: centos
command: ["/bin/sh"]
args: ["-c", "while true; do echo $(date -u) >> /data/out; sleep 5; done"]
volumeMounts:
- name: persistent-storage
mountPath: /data
volumes:
- name: persistent-storage
persistentVolumeClaim:
claimName: efs-claim
$ kubectl apply -f efs-test-pod.yamlPod 가 생성되고 Pod 로 접속하면 /data/out 파일에 시간이 출력되고 있으면 정상적으로 작동하는 것이다.
PVC 를 생성할 때 accessModes 가 ReadWriteMany 인 것도 확인하자.
이제 필요한 사전 구성은 마쳤으니 chart 로 설치를 진행한다.
먼저 chart 를 등록하고 다운 받는다.
$ helm repo add harbor https://helm.goharbor.io
$ helm repo update
$ helm fetch harbor/harbor --untar차트를 다운 받을 필요는 없으니 관련 values.yaml 을 확인하기 위해서 참고용으로 다운 받았다.
필요한 value 를 설정한다.
$ vi ask-values.yaml
---
harborAdminPassword: "xxxxx"
expose:
type: ingress
tls:
enabled: true
certSource: secret
secret:
secretName: "taco-cat-tls"
ingress:
hosts:
core: harbor.xxx
className: "nginx"
externalURL: https://harbor.xxxharborAdminPassword 는 Harbor 웹 화면에서 admin 계정으로 접속할 때 필요한 패스워드 이다.
expose 는 ingress 에 노출되는 값이며 도메인이 harbor.xxx 으로 DNS 에 연결되어 있으며 (DNS 가 없으면 로컬 컴퓨터에 /etc/hosts 파일에 등록해서 사용한다), 도메인 인증서는 앞에서 생성한 harbor-ask 네임스페이스에 taco-cat-tls 라는 secret 이름으로 저장되어 있다.
persistence:
enabled: true
resourcePolicy: "keep"
persistentVolumeClaim:
registry:
storageClass: "taco-efs-storage"
accessMode: ReadWriteMany
size: 1024Gi
jobservice:
jobLog:
storageClass: "taco-efs-storage"
accessMode: ReadWriteMany
size: 128Gi
redis:
storageClass: "taco-efs-storage"
accessMode: ReadWriteMany
size: 256Gi
trivy:
storageClass: "taco-efs-storage"
accessMode: ReadWriteMany
size: 128Gi
imageChartStorage:
disableredirect: false
type: filesystem
filesystem:
rootdirectory: /storagepersistence 는 Harbor 컴포넌트에서 사용하는 스토리지 정보이다. Harbor 차트에서 설치하는 컴포넌트는 registry , jobservice , redis , trivy , core, portal 등이 있으며 스토리지가 필요한 컴포넌트만 기술하면 된다.
registry:
replicas: 2
portal:
replicas: 2
core:
replicas: 2
jobservice:
replicas: 2
trivy:
enabled: true
replicas: 2
notary:
enabled: false
cache:
enabled: true
expireHours: 24각 컴포넌트의 Pod 갯수를 넣는다. HA 구성 이므로 최소 2 이상을 넣는다.
notary 는 이미지 서명 관련 컴포넌트로 이번 구성에서는 설치하지 않았다.
database:
type: external
external:
host: xxxxxx.ap-northeast-2.rds.amazonaws.com
port: "5432"
username: "harbor"
password: "xxxxxxx"
coreDatabase: "registry"RDS 에 만들어진 외부 데이터베이스 정보를 넣는다.
redis:
type: internal레디스는 내부에서 단일 Pod 로 생성한다.
전체 values 는 다음과 같다.
$ vi ask-ha-values.yaml
---
harborAdminPassword: "xxxxxx"
expose:
type: ingress
tls:
enabled: true
certSource: secret
secret:
secretName: "taco-cat-tls"
ingress:
hosts:
core: harbor.xxx
className: "nginx"
externalURL: https://harbor.xxx
persistence:
enabled: true
resourcePolicy: "keep"
persistentVolumeClaim:
registry:
storageClass: "taco-efs-storage"
accessMode: ReadWriteMany
size: 1024Gi
jobservice:
jobLog:
storageClass: "taco-efs-storage"
accessMode: ReadWriteMany
size: 128Gi
redis:
storageClass: "taco-efs-storage"
accessMode: ReadWriteMany
size: 256Gi
trivy:
storageClass: "taco-efs-storage"
accessMode: ReadWriteMany
size: 128Gi
imageChartStorage:
disableredirect: false
type: filesystem
filesystem:
rootdirectory: /storage
registry:
replicas: 2
portal:
replicas: 2
core:
replicas: 2
jobservice:
replicas: 2
trivy:
enabled: true
replicas: 2
notary:
enabled: false
cache:
enabled: true
expireHours: 24
database:
type: external
external:
host: xxxxxx.ap-northeast-2.rds.amazonaws.com
port: "5432"
username: "harbor"
password: "xxxxxxx"
coreDatabase: "registry"
redis:
type: internal쿠버네티스에 배포한다.
$ helm upgrade -i harbor-ask harbor/harbor --version 1.12.3 -n harbor-ask -f ask-ha-values.yamlHarbor 웹에 접속하여 사용자(tks)와 프로젝트(tks)를 만든다.
해당 프로젝트의 Members 탭에는 사용자가 등록되어 있어야 한다. (그래야 컨테이너 이미지를 올릴 수 있는 권한이 있다)
$ docker login harbor.xxx -u tks
Password:
$ docker pull hello-world
$ docker tag hello-world harbor.xxx/tks/hello-world
$ docker push harbor.xxx/tks/hello-world
 Seungkyu Ahn's Blog, Kubernetes, Container, CNCF, OpenStack, Linux, Programming and so on by seungkyua@gmail.com |
||


|




{kind=link}
{kind=link}